El expediente es el siguiente: contrariamente a todo sentido común copiar una estructura de 21 campos double tardaba menos, pero mucho menos, que copiar una clase.
El expediente X
Tengo una clase y una estructura equivalentes: simplemente 21 propiedades de tipo double con get y set. Nada más. La clase se llama Point21D y la estructura Point21DStruct.
Luego, tengo dos classes (World21D y World21DStruct) con el mismo código salvo, que la primera usa Point21D y la segunda Point21DStruct:
|
|
Ahora viene lo bueno… Ejecuto el siguiente código dos veces (en la primera _world es la clase World21D y en la segunda es la estructura World21DStruct:
|
|
Estaba preparado para que la versión con struct fuese más lenta, porque copiar los 21 campos es más lento que copiar la referencia… Pero usando BenchmarkDotNet obtuve eso:
| Method | Mean | Error | StdDev |
|----------------------- |----------:|---------:|---------:|
| ReadAllPointsAsClasses | 447.11 us | 8.348 us | 8.199 us |
| ReadAllPointsAsStructs | 27.57 us | 0.606 us | 0.722 us |
¡No tiene sentido alguno! Estoy usando .NET Core 3.1 y compilado en Release y a ver, por muy optimizado que esté, no puede ser que copiar una referencia tarde 20 veces más que copiar la estructura de 21 campos ;)
No era un problema de BenchmarkDotNet, el profiler me daba exactamente el mismo resultado. En este caso el método One usa la versión con la clase y el método Two la versión con la estructura:
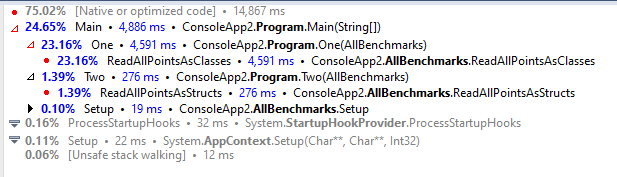
Se puede ver como la versión con clases tarda unas 20 veces más que la versión con estructuras (23.16% vs 1.39%). Los tiempos variaban cada vez, pero el patrón era siempre ese. Está claro que ahí había algo.
Quité BenchmarkDotNet del proyecto (raro, pero podría ser que igual algo de lo que añade al proyecto causara esa variación) ,pero el resultado era exactamente el mismo.
El “culpable”
Debía entender qué es lo que estaba ocurriendo, por qué la lectura en el caso de las clases tardaba tanto…Era hora de sacar la artillería pesada.
Lo primero verificar con IlSpy que no hubiera nada raro (alguna optimización del compilador que pudiera explicar eso), pero no, todo parecía “correcto”:

Descartada cualquier optimización del compilador, usé ildasm para ver el código decompilado de ambos métodos:
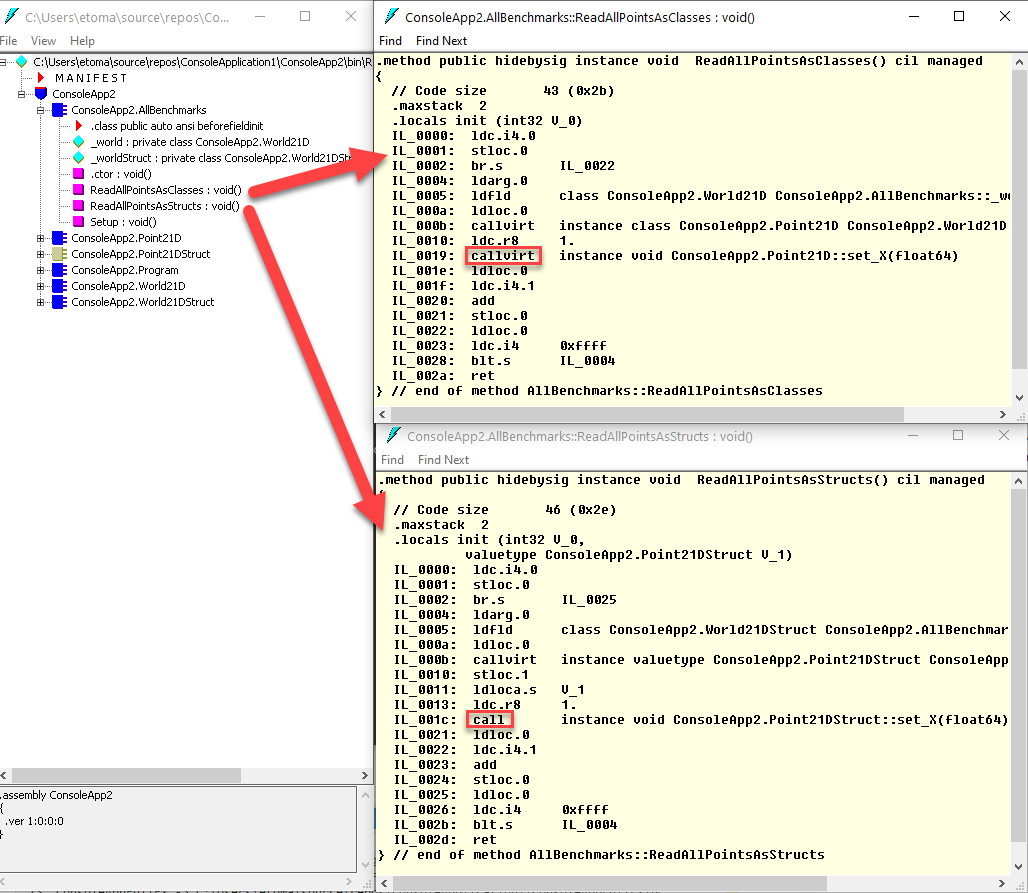
El listado superior es el IL del método ReadAllPointsAsClasses y el segundo el del método ReadAllPointsAsStructs. Son bastante parecidos, pero hay una diferencia fundamental. En la versión que usa clases tenemos:
callvirt instance void ConsoleApp2.Point21D::set_X(float64)
Mientras que en la versión que usa estructuras:
call instance void ConsoleApp2.Point21DStruct::set_X(float64)
Esa línea es la que invoca el setter de la propiedad X del objeto. Recuerda que los métodos ReadAllPointsAsClasses /ReadAllPointsAsStructs tenían el mismo código fuente:
|
|
Es este p.X = 1; el que marca la diferencia. En el caso de clases usa callvirt y en el de estructuras usa call. ¿Cual es la diferencia? Pues bien, hay dos diferencias fundamentales entre callvirt y call:
callvirtpermite llamar a métodos que pueden ser redifindos en una clase hija. Es decir, a los métodos virtuales.callvirtverifica que el puntero no seanull(callno comprueba nada).
A pesar de que el nombre de callvirt sugiera que solo se usa en mètodos marcados con virtual, la realidad es que dado que callvirt verifica que this no sea null el compilador lo usa en cualquier llamada a método… excepto si el objeto es un Value object (o sea una estructura) que nunca puede valer null. Es por eso que en la versión que usa estructuras se usa call.
Bueno, para verificarlo lo más sencillo es eliminar esta línea p.X = 1 y ver qué ocurre:

¡Vaya cambio! Ahora la lectura de estructuras ocupa el 97% de mi tiempo, mientras que la lectura de las clases ocupa menos del 2%.
¿Y en tiempos? Pues habilitando BenchmarkDotNet otra vez, esos son los resultados:
| Method | Mean | Error | StdDev |
|----------------------- |------------:|----------:|----------:|
| ReadAllPointsAsClasses | 26.81 us | 0.204 us | 0.181 us |
| ReadAllPointsAsStructs | 1,305.62 us | 16.884 us | 15.793 us |
Leer las estructuras es mucho más costoso que leer las clases. ¡Misterio resuelto!
Corolario
Ese expediente X no hubiese sido tal si yo no me hubiera saltado las reglas más fundamentales cuando quieres analizar código. A saber:
- Analiza una sola cosa cada vez. En mi caso analizaba dos (obtener un objeto y llamar a una propiedad).
- No des NADA por sentado. En mi caso supuse que la línea
p.X=1no afectaba, ya que “hacía” lo mismo. Y bueno, ya véis… ni por asomo xD
Y recordad: ¡medid siempre! (pero medid bien, no os pase como yo xD), que con temas de rendimiento… ¡nunca se sabe! ;-)
