Antes de hablar sobre como podemos crear operaadores para Kubernetes, vamos a ver qué entendemos por un operador, para qué lo podemos usar y qué ventajas nos aporta respecto otros mecanismos similares. ¡Vamos allá!
Un operador es un mecanismo para manejar y desplegar aplicaciones para Kubernetes. La palabra clave, aquí es “para”. No estamos hablando de desplegar una aplicación en un Kubernetes, si no de desplegar una aplicación para Kubernetes. Este “para” implica, no solo que el despliegue lo efectuamos mediante kubectl si no que también efectuamos el mantenimiento y configuración. O sea, la aplicación se instala, mantiene y configura usando la API de Kubernetes y todas las herramientas asociadas (con el mencionado kubectl a la cabeza).
Este concepto fue introducido por la gente de CoreOS y se basa en dos conceptos fundamentales de Kubernetes que debemos entender para poder comprender como funcionan los operadores:
- Recursos: Un recurso en Kubernetes es un objeto que define un estado deseado. Por ejemplo, el recurso
ReplicaSetpermite definir que se quiere tener siempre en ejecución un número determinado de pods. - Controladores: Un controlador en Kubernetes se encarga de monitorizar a un recurso y asegurarse que el estado real del clúster es compatible con el estado deseado por el recurso y tomar las acciones necesarios en caso de que eso no sea así. Por ejemplo el controlador de
ReplicaSetse encarga de asegurar que el número de pods reales en ejecución son los definidos por el recursoReplicaSetasociado, creando o destruyendo pods según sea necesario.
Controladores en Kubernetes
Los recursos los manejamos a través de los ficheros YAML, mientras que los controladores son código que se ejecuta en el clúster. A grandes rasgos podemos ver un controlador como un “bucle sin fin” que realiza los siguientes pasos:
- Consulta el estado actual del clúster
- Si el estado actual es el deseado, no hace nada en esta iteración
- En caso contrario, usa la API de Kubernetes para modificar el estado del clúster
Una representación más completa se puede observar en el siguiente diagrama:
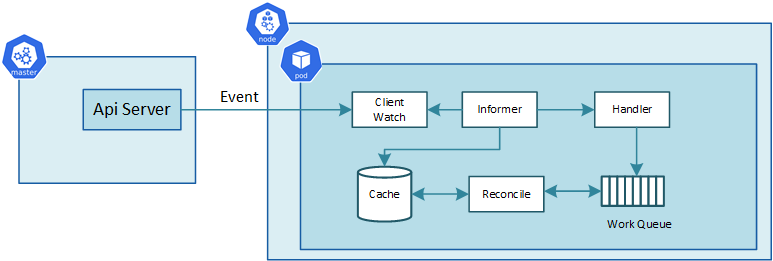
Este esquema, adaptado de la documentación oficial, muestra con un poco más de detalle como funciona un controlador (basado en los componentes que define la librería client-go). Introduzco todos esos términos porque son relevantes en el caso de que quieras buscar información de como crear controladores.
- El controlador se suscribe a determinados eventos de la API de Kubernetes para monitorizar creaciones, borrados y actualizaciones de recursos
- A cada tipo de recurso se le asigna un informer que recibirá solo los eventos del tipo de recurso especificado
- El evento se guarda en una cola de trabajo a la vez que el estado del objeto se guarda en una cache
- Finalmente la lógica de reconciliación recoje el evento de la cola, el estado del objeto de la cache y actualiza el clúster (llamando a la API) si es necesario
El diagrama anterior contiene un detalle importante: los operadores se ejecutan en pods. Por lo tanto, instalar un operador es simplemente desplegar los ficheros YAML en Kubernetes.
Controladores vs Operadores
Todos los operadores usan el patrón de controlador y por lo tanto definen algún operador. Pero no todos los controladores son operadores. Puedes usar un controlador “por si solo”, cuando quieras reaccionar a un tipo de recurso, pero los operadores van más allá. En concreto los operadores:
- Definen uno o más controladores
- Definen uno o más CRDs
- Manejan el ciclo de vida
- Están orientados a una aplicación
Resalto el último punto porque es importante: un operador está destinado a una aplicación. Si esa aplicación requiere otras aplicaciones deberías usar otros operadores para esas otras aplicaciones. Un ejemplo: puedes tener un operador que se encargue de instalar, no sé, un wordpress. Pero si wordpress depende de mysql, deberías usar otro operador para mysql. Un operador por aplicación.
Los otros tres puntos son importantes también y ponen de manifiesto las diferencias entre operadores y controladores: un operador es un (o más de un) controlador más un conjunto de CRDs que permiten configurar y mantener la aplicación usando la API de Kubernetes. Finalmente, un operador suele manejar el ciclo de vida de la aplicación que controla creando y destruyendo aquellos pods necesarios.
Pongamos como ejemplo el operador de Prometheus. Este operador instala varios CRDs, entre los que destacan uno llamado monitoring.coreos.com/v1/Prometheus que representa al propio Prometheus y otro llamado monitoring.coreos.com/v1/ServiceMonitor que define qué servicios debe monitorizar Prometheus. Si instalas el operador de Prometheus, para desplegar un Prometheus no debes crear ningún deployment, solo debes crear un CRD de tipo Prometheus. La siguiente imagen muestra un prometheus llamado k8s desplegado en el espacio de nombres monitoring:
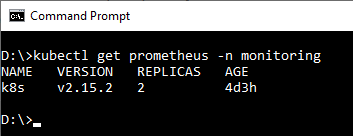
Observa como el propio CRD de Prometheus define las replicas (en este caso 2), y es el propio operador el que se encarga de crear y destruir los pods (no hay ningún deployment ni replicaset para Prometheus).
Operadores vs Helm
¿No se supone que para instalar aplicaciones en Kubernetes tenemos a Helm? Hay un cierto solapamiento entre algunas de las responsabilidades de un operador y de las de Helm: en ambos casos tenemos mecanismos para manejar workloads complejos. Si instalar tu aplicación es un proceso de un solo paso y no se requiere que esta se maneje a través de objetos de Kubernetes, entonces Helm es el mecanismo a utilizar. Por otro lado, si tu aplicación requiere que el mantenimiento de esta se realice a través de objetos de Kubernetes, entonces deberías usar un operador. Observa que, dado que instalar un operador es poco más que desplegar sus YAML, no hay nada que te impida usar Helm para desplegar el operador que te permitirá desplegar tu aplicación.
Es buena práctica instalar los CRDs que use tu operador mediante YAML (en lugar de hacerlo en el código del operador). La razón es por seguridad: instalar un CRD requiere permisos de clúster, mientras que tu operador seguramente no los requiere para hacer su trabajo. Si instalas los CRDs mediante código, el pod que ejecuta tu operador requerirá permisos de clúster solo para este paso, rompiendo el principio de mínimo privilegio. Así, puedes definir todos los CRDs en un chart de Helm, que los instale, junto con el deployment que ejecute tu operador y el resto de elementos necesarios. Eso sí, ten presente que debes indicarle a Helm que instale los CRDs antes que el resto de elementos, si no tendrás problemas. El cómo hacer esto difiere de si usas la versión 2.x o 3.x de Helm).
Conclusión
Con este primer post de la serie cubrimos lo básico que necesitas saber sobre operadores en Kubernetes. En el resto de posts veremos como crear un operador y ¡como desplegarlo en nuestro cluster!
