Uno de los aspectos vitales cuando tienes tu Kubernetes en marcha, es tener un plan de backup y restore para las cargas de trabajo ejecutándose en él. Hay dos aspectos principales a considerar:
- Backup de los propios objetos del cluster: Tener copias de seguridad de todos los objetos (incluyendo CRDs) que se están ejecutando en el clúster. De este modo ante una pérdidad de datos que involucre dichos objetos, los podrás restaurar en el estado en el qué estaban.
- Backup de los datos en volúmenes persistentes.
Ambos puntos son importantes, pero el 2 es crítico. Ante la pérdida de datos de un clúster, es posible que puedas restaurar los objetos de éste a partir de los scripts de despliegue, charts de helm, pipelines de CI/CD, pero si pierdes los datos de un volumen persistente entonces estás en problemas serios.
Volúmenes persistentes y aprovisionamiento dinámico
Una de las estrategias más recomendades en Kubernetes que están en la nube (como AKS en nuestro caso) es usar aprovisionamiento dinámico de volúmenes persistentes, eso significa que el propio clúster creará los recursos necesarios para almacenar dichos datos. P.ej.en AKS lo habitual es que cada volúmen persistente esté respaldado por un disco:
En este caso cada volúmen persistente (PV) se crea automáticamente a partir de un PVC declarado por algún pod y la creación del volúmen persistente lleva a la creación del disco subyacente en Azure (en el grupo de recursos MC_*). En la mayoría de casos esos volúmenes persistentes se declaran con una reclaim policy de “Delete” lo que significa que tan buen punto el PV se elimine, lo hará el disco. Y el PV se eliminará si se elimina el PVC (recuerda pero, que el ciclo de vida de un PVC es independiente del ciclo de vida del pod). En resumen:
- Eliminar un pod no elimina el PVC, por lo tanto no elimina el PV y los datos siguen en el disco. Futuros pods que usen este PVC seguirán teniendo acceso a los datos (lo que es habitual en el caso de StatefulSets).
- Eliminar el PVC, elimina el PV y si la reclaim policy es “Delete”, entonces se elimina el disco virtual en Azure.
Veamos un ejemplo de dicho aprovisionamiento dinámico (en este post supongo que se usa AKS). Tienes un PVC tal como el siguiente:
|
|
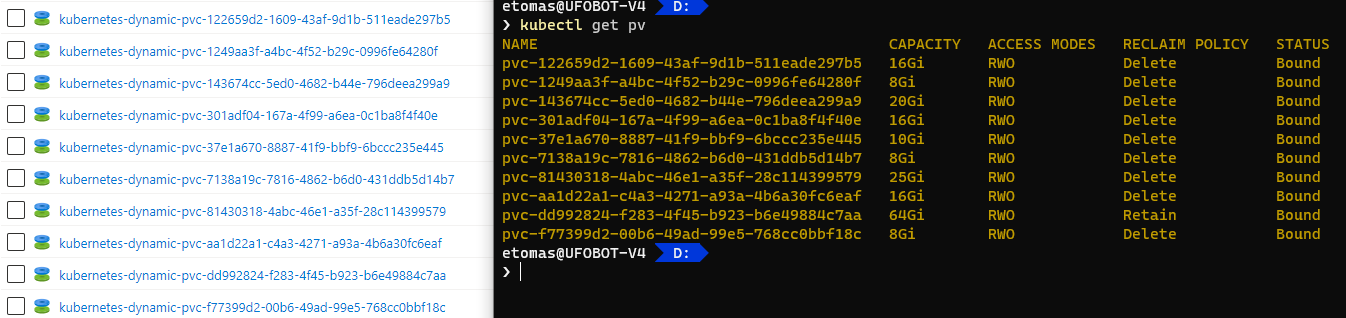
En el momento en qué despliegue este PVC se creará un PV vinculado a dicho PVC (observa la columna CLAIM):
> kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-6da16723-7462-4117-b4bf-5d9fe4b06c50 5Gi RWO Delete Bound default/test-pvc default 2s
En este momento el disco en Azure ya está creado, a pesar de que nadie usa dicho volumen persistente (ningún pod ha reclamado el PVC), el PV ya está creado y enlazado al PVC.
En este momento puedes desplegar un deployment que reclame este PVC test-pvc:
|
|
En este momento el directorio /usr/share/nginx/html del contenedor está vinculado al PVC test-pvc y por lo tanto al PV pvc-6da16723-7462-4117-b4bf-5d9fe4b06c50 que se ha creado automáticamente y que se respalda en el disco de Azure creado. Si ahora borras el deployment, el PVC persiste ya que su ciclo de vida es independiente, por lo que si luego recreas el deployment otra vez, el nuevo pod que se creará continuará teniendo los datos. Por lo tanto, no te confundas:
El ciclo de vida de un PVC es independiente al de los pods, y el volúmen persistente (PV) existirá mientras exista el PVC. Si la Reclaim Policy es “Delete” el disco de Azure se borrará al eliminarse el PV.
Bien, ahora hay dos escenarios posibles que nos pueden llevar a una pérdida de datos.
Problema: corrupción de los datos de un PV
Eso ocurre porque, por cualquier motivo, los datos del PV (del disco de Azure vamos) se han corrompido. Esto puede ser debido a un fallo de código del propio pod (y ha borrado datos que no debería haber borrado) o bien a qué el disco de Azure que hay por debajo, por cualquier, motivo ha fallado. En este caso debemos restaurar los contenidos del disco. Vamos a ver como podemos hacer esto. Para ello, obviamente, antes debemos tener una copia de seguridad, en forma de snapshot del disco a restaurar. Así, que ya sabes: lo primero es hacer snapshosts de los discos de todos tus PVs de forma periódica. Hay muchas maneras de hacerlo, pero si quieres empezar por algo sencillo aquí tienes un script de PowerShell que realiza esos snapshots. Lo puedes invocar de la siguiente manera:
.\Perform-Pvc-Backup.ps1 -rg <grupo-recursos-aks> -destinationRg <grupo-recursos-backup> -pvcsToBackup <pvcs-a-guardar>
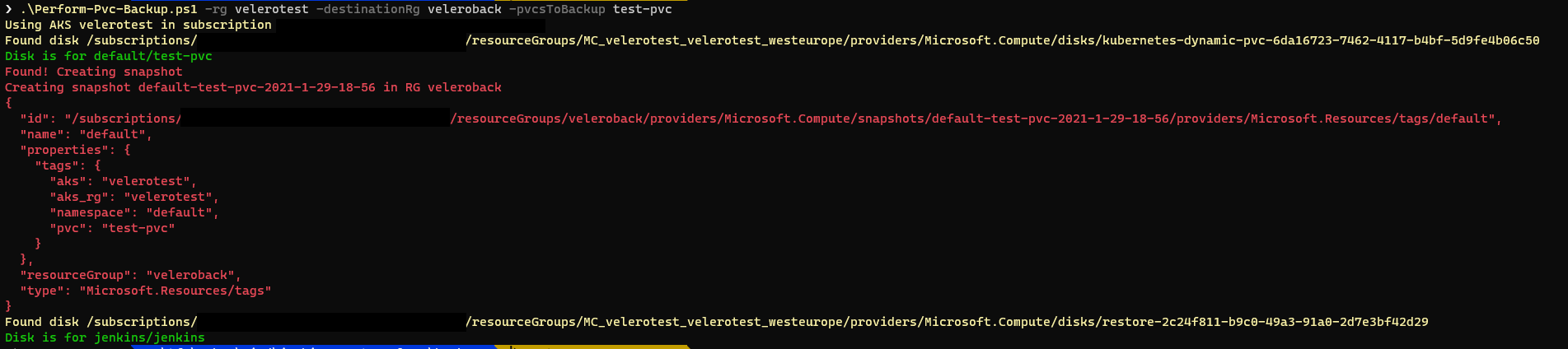
En mi ejemplo el Kubernetes tenía dos PVCs, pero solo creo he indicado que quiero guardar test-pvc. El resultado será que en el grupo de recursos especificado en -destinationRg tendrás snapshots de los PVCs indicados:

Recuperando los datos usando el plugin de Azure Disk
Si debemos restaurar un disco a partir de este snapshot, el proceso es bastante manual. Para ello:
- El primer paso es crear un disco a partir del snapshot. Si usas zonas de afinidad en el AKS, elige una para el disco.
- Luego en el pod debemos indicar que queremos crear un volumen a partir de un
azureDisk, no de unpersistentVolumeClaim:
|
|
Asegúrate de que restauras el disco en un grupo de recursos en el que el AKS tenga acceso (lo ideal es el grupo
MC_).
¡Otro apunte importantísimo! Si usas zonas de afinidad en el AKS, debes asegurarte que el pod se ejecuta en la misma zona de afinidad en la cual has restaurado el disco. Para ello deberás usar node affinity para forzar la ejecución del pod en un nodo que esté en la misma zona de afinidad que el disco restaurado. P. ej. si tu región es westeurope y el disco lo has restaurado en la zona de afinidad 1, debes usar la siguiente definición de afinidad:
|
|
¡Y listos! El nuevo pod ya está conectado al disco restaurado a partir del snapshot y sigues teniendo los datos.
Ahora bien, quiero mencionar algunas cosas de como queda el AKS después de esto: Esto NO usa un PV por debajo. Con est configuración el volumen del pod está enchufado directamente al disco indicado. No se usa ni el PV ni el PVC (no son ni necesarios).
El inconveniente de este modelo es que el estado del AKS es distinto después de restaurar: antes tenía un volumen contra un PVC (y un PV) y después de restaurar lo que tengo es un volumen enchufado a un disco. He recuperado los datos, pero a nivel de objetos del cluster, la configuración es distinta.
Recuperando los datos usando otro PV
Otra opción es usar otro PV para restaurar los datos. Para ello, necesitas crear el PV a mano:
|
|
Es importante que storageClassName y capacity.storage tengan los valores correctos (los que correspondan al tipo de disco usado y su tamaño). En mi caso al restaurar el snapshot el tamaño del disco era de 8Gb así que ese es el valor que he usado y el tipo de disco era Premium SSD que se corresponde a la storage class managed-premium. Esto define un PV que se ata a un PVC llamado restoredpvc (valor de spec.claimRef.name). Si aplicas este YAML al cluster verás que el PV está creado, pero no está “enlazado” (columna STATUS):
> kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mypv 8Gi RWO Delete Available default/restoredpvc managed-premium 4s
En este punto debo volver a hablar de las zonas de afinidad. Si usas afinidad en el AKS, debes asegurarte que el volumen persistente incluya un nodeSelector que seleccione los nodos que están en la misma zona de afinidad que el disco. En mi caso al restaurar el disco, elegí la zona 1, de ahí que tenga la selección de zona
westeurope-1.
Bien, ahora el siguiente punto es crear el PVC:
|
|
Observa como el PVC tiene el nombre que hemos usado en spec.claimRef.name del PV y la misma clase y tamaño (esos 8Gb). Ahora tan buen puntos apliques el fichero YAML del PVC al cluster, el estado del PV pasará de Available a Bound:
> kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
mypv 8Gi RWO Delete Bound default/restoredpvc managed-premium 109s
Ahora, ya podemos usar el mismo yaml que teníamos originalmente, solo tenemos que modificar el nombre del PVC para que sea restoredpvc en lugar de test-pvc al definir el volumen en el pod.
Editado el 30/01/2001: En un caso yo tuve que forzar que el pod se ejecute en la misma zona de afinidad que el PV que va a enlazar, ya que se me quedó pending todo el rato. Es cierto que el pod debe ejecutarse en la misma zona de afinidad donde está el disco, ya que si no no se puede enlazar el disco al nodo. Pero, según tengo entendido, Kubernetes se encarga de eso, y en todos los ejemplos posteriores que hice, no tuve que usar
nodeAffinityen el pod: al usar el pod un PV que estaba en la zona 1 (el PV si debe tener definida la afinidad), el scheduler garantiza que el pod se ejecuta en un nodo que esté en la misma zona de afinidad. Pero, como digo, en un caso no me funcionó (no tengo claro el porqué todavía), así que si tenéis ese problema, que sepáis que podéis solucionarlo usandonodeAffinity. Si tengo más info, lo haré saber :)
Bien, si ahora creas el deployment de nuevo, el pod se enlazará al disco restaurado vía el PVC restoredpvc que usa el PV mypv que tiene el disco resaturado.
El estado final del AKS ahora es más similar a como estaba antes, ya que seguimos teniendo un PV y un PVC, la diferencia es que antes el PV era autoaprovisionado (se creaba a partir del PVC) y ahora el PV es estático. Pero al margen de eso no hay más diferencia.
¡Listos! En este post hemos explorado el uso de snapshots para hacer copias de nuestros PVs y pode restaurarlas. Pero ¡eh! eso no es todo! En el siguiente post exploraremos como podemos automatizar todo este proceso, y de paso hacer copias de seguridad de los objetos del cluster usando velero.
